网上有很多快递查询接口,如快递100、快递鸟等等,但使用接口并不是免费的,如何爬取免费查询快递物流呢,本文仅仅提供爬虫爱好者一个爬虫思路,仅供交流学习请勿用于商业用途。
页面地址: https://www.baidu.com/baidu?isource=infinity&iname=baidu&itype=web&tn=02003390_43_hao_pg&ie=utf-8&wd=%E5%BF%AB%E9%80%92
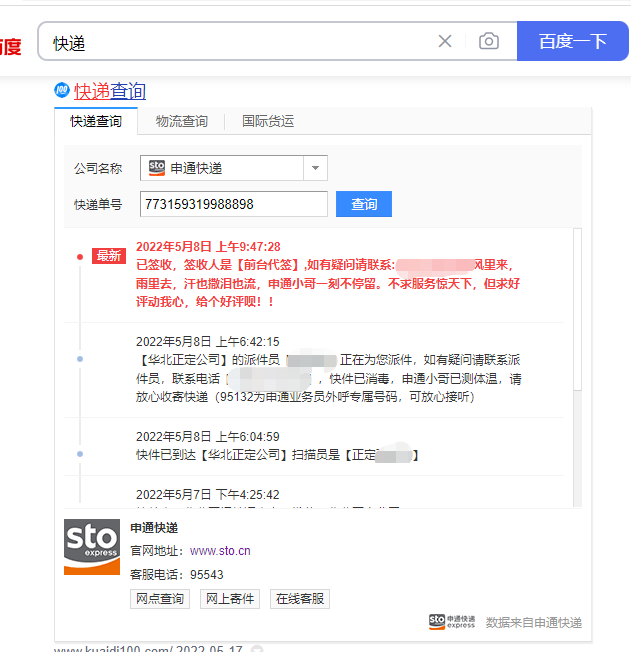
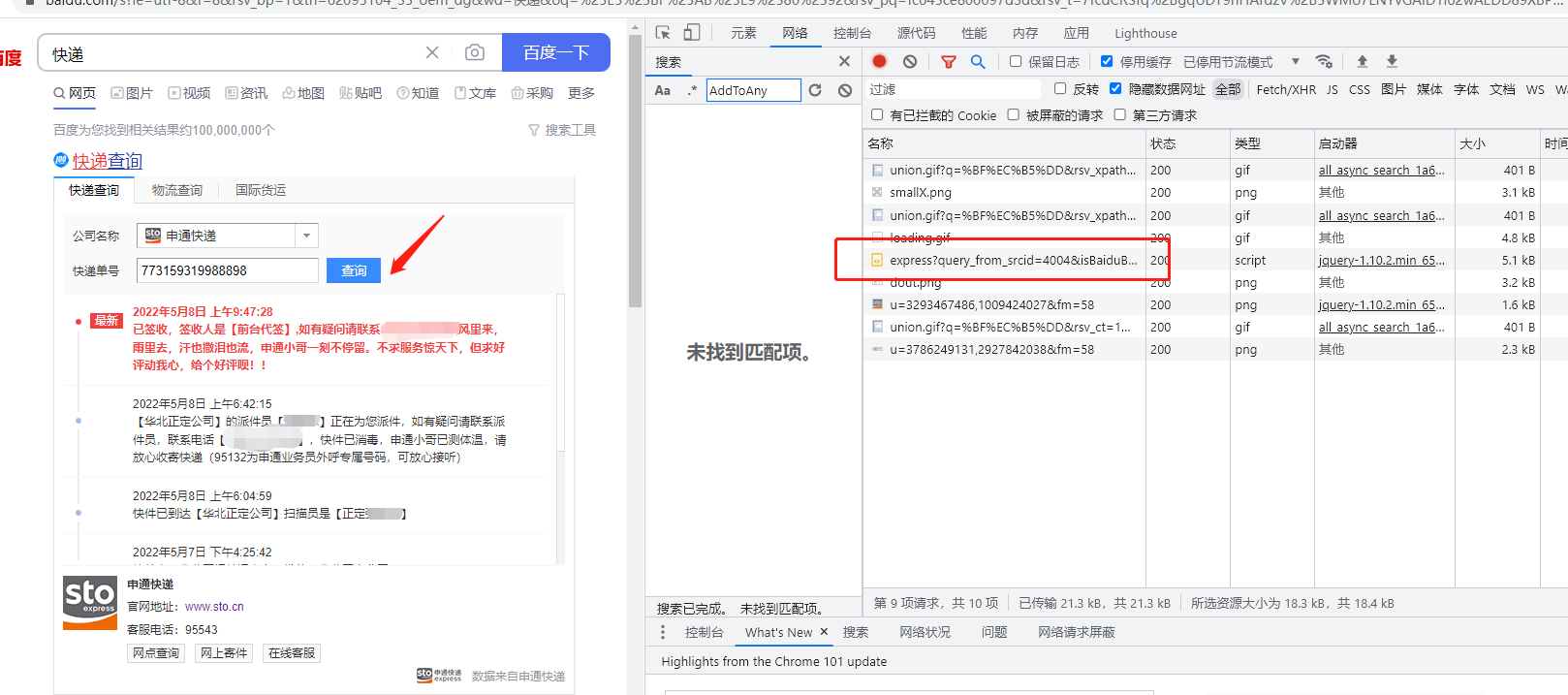
那么如何解析这个地址呢,右键打开开发者模式,再次点击查询,会发现有新增加的请求地址。如下图:
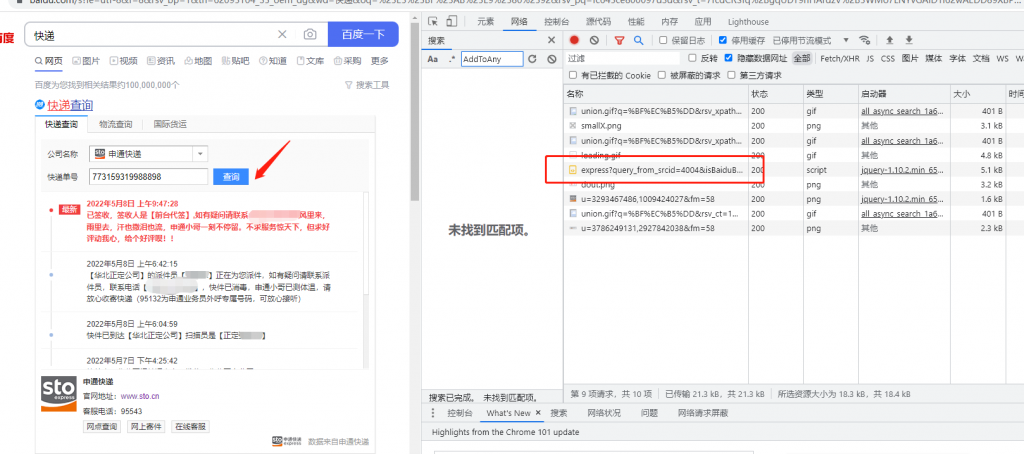
我们点击该链接,打开预览可以预览响应信息。如下图:
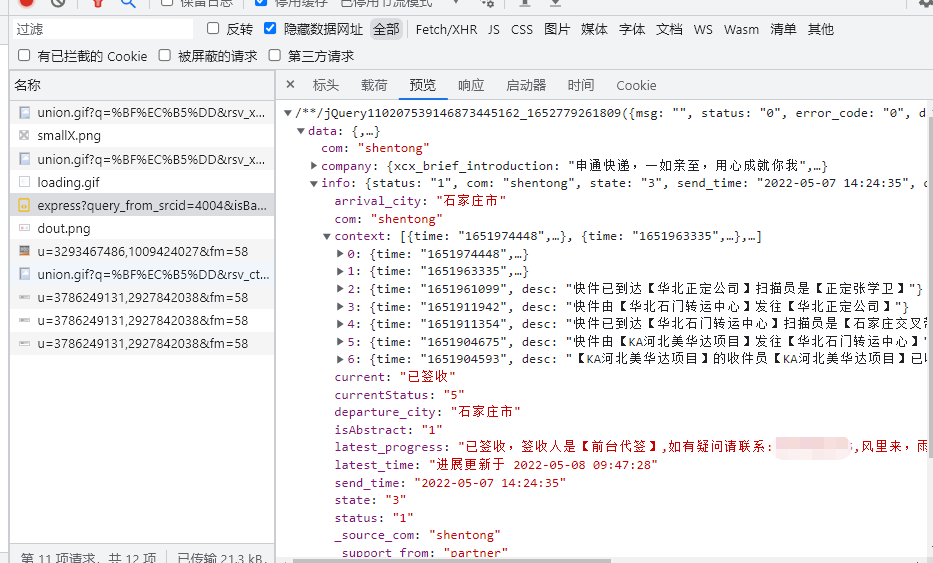
那么这个就是输出给百度这个页面的信息,这个地址就是正确快递信息请求地址。
看标头该地址请求为get请求,如下图:
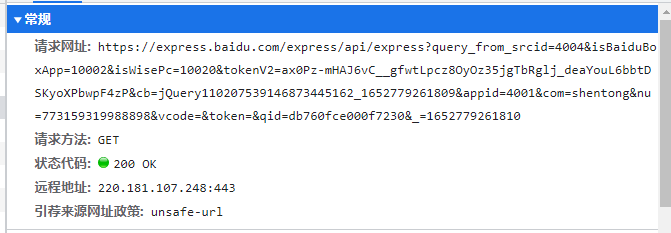
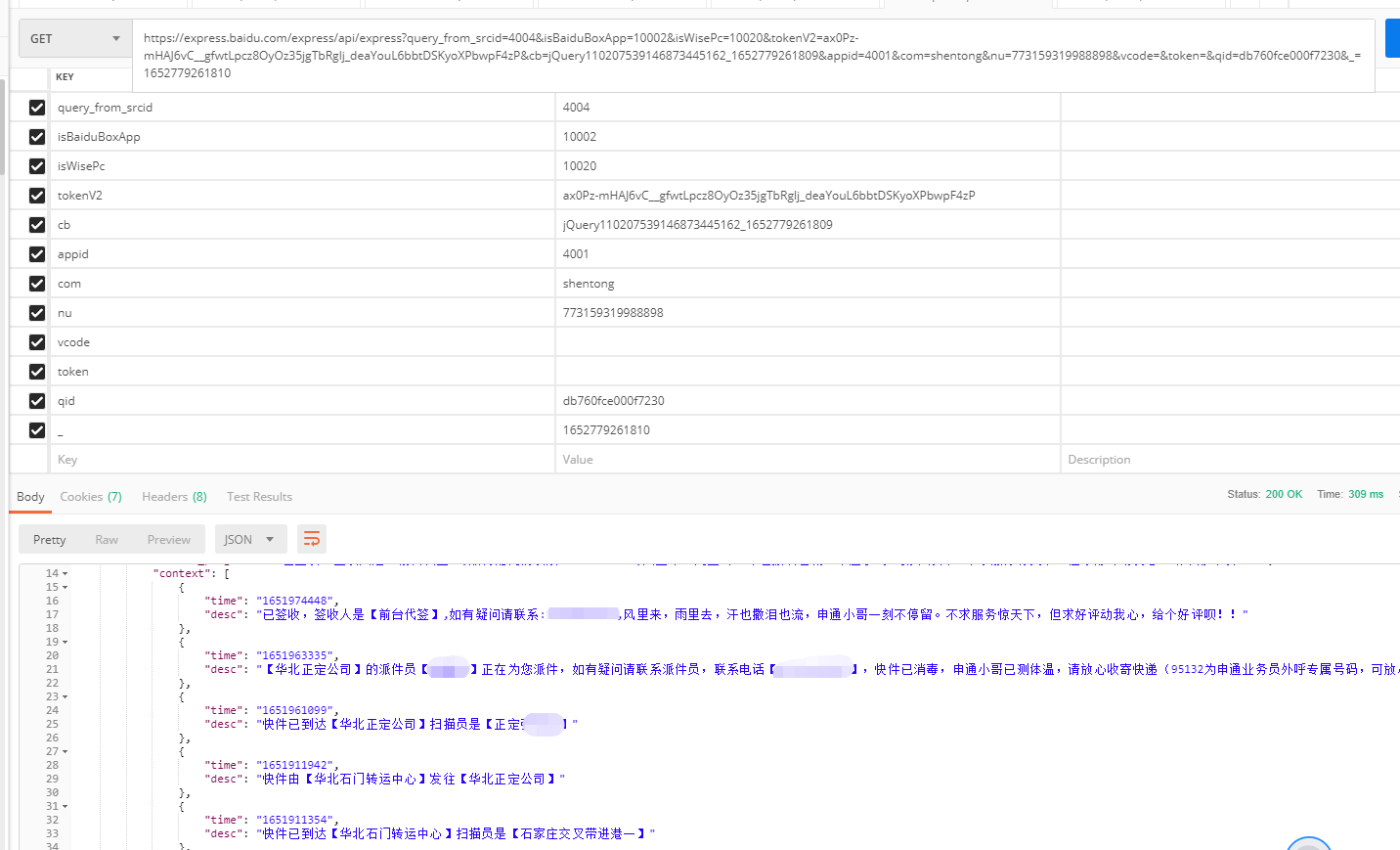
故复制该地址用postman打开,也可以用其他测试接口软件。如下图:
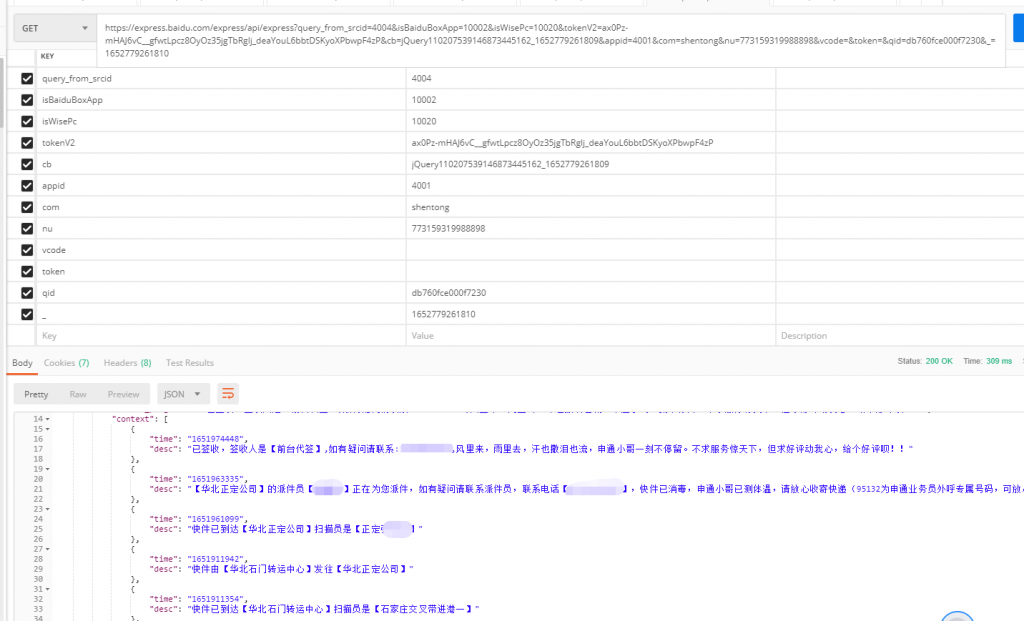
可以看见正确返回了快递信息。
筛选无用参数发现必填参数为tokenV2和nu,如下图:
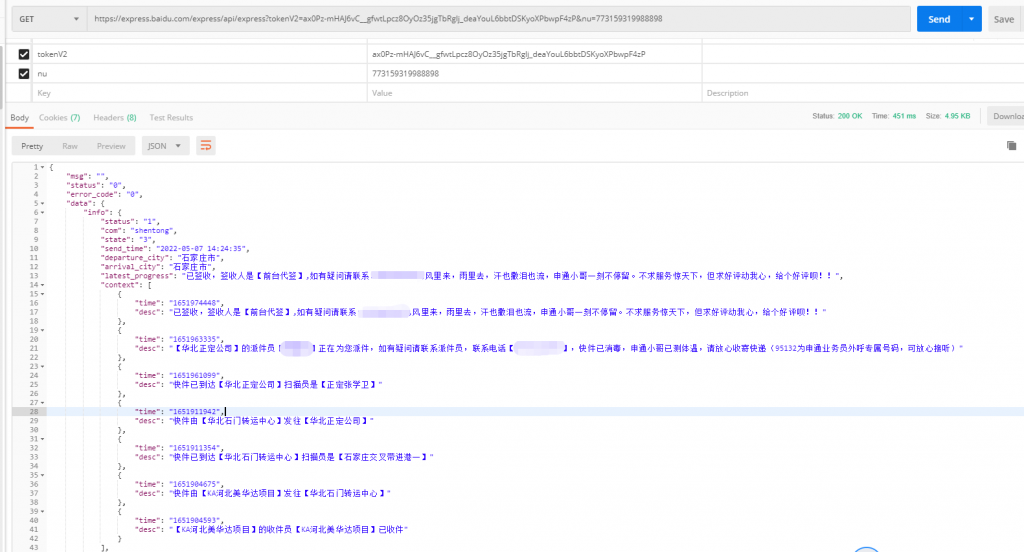
地址为:https://express.baidu.com/express/api/express?tokenV2=ax0Pz-mHAJ6vC__gfwtLpcz8OyOz35jgTbRglj_deaYouL6bbtDSKyoXPbwpF4zP&nu=773159319988898
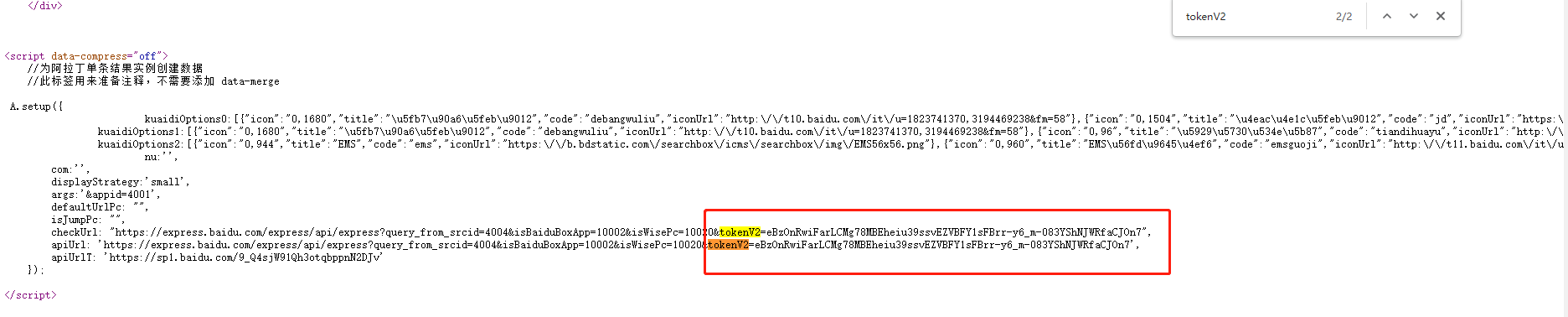
nu为快递单号,tokenV2是如何生成的我们需要找一下,因为到目前为止我们只打开了一个百度快递页面,那么我选择检查源码,看看是否有用的到的信息。
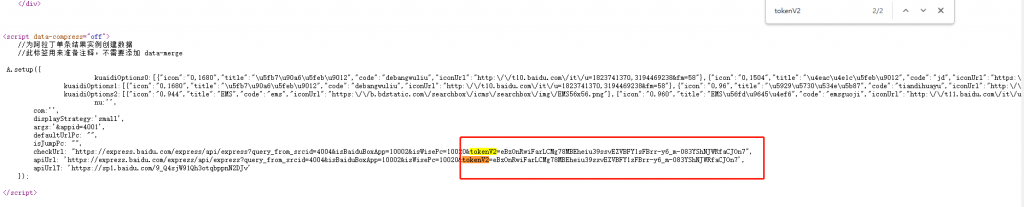
搜索tokenV2果然找到了有用信息,前面页面刷新了一下,所以tokenV2发生了改变,可以再次打开检查上下图是一样的。

所以整个获取快递信息的接口和必填参数已经知道了。首先在快递页面源码里面获取tokenV2,之后与 https://express.baidu.com/express/api/express?tokenV2=tokenV2&nu=单号 即可。下面我用一个简单php程序,复盘一下。
获取tokenV2
public function getinfo(){
$url = 'https://www.baidu.com/s?tn=02003390_43_hao_pg&ie=utf-8&wd=%E5%BF%AB%E9%80%92';
$header = array (
"Host:www.baidu.com",
"Content-Type:application/x-www-form-urlencoded",//post请求
"Connection: keep-alive",
'Referer:http://www.baidu.com',
//关键作用User-Agent 可是每次爬取结果都是无法爬取到百度搜索的内容,要验证 user-agent没有模拟好,所以不行。
'User-Agent: Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 Safari/537.36'
);
$ch = curl_init ();
curl_setopt ( $ch, CURLOPT_URL, $url );
curl_setopt ( $ch, CURLOPT_HTTPHEADER, $header );
curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, 1 );
$content = curl_exec ( $ch );
if ($content == FALSE) {
echo "error:" . curl_error ( $ch );
}
curl_close ( $ch );
// return $content;
$pattern = '/tokenV2=(.*?)"/i';
preg_match($pattern, $content, $match);
return $match[1];
}获取这个tokenV2,curl或者这个页面源码通过正则获取tokenV2,
如果不加tn参数,会有百度安全验证,这样无法获取会不稳定。
tn– 提交搜索请求的来源站点。一个有用的tn:tn=baidulocal 表示百度站内搜索,返回的结果是很干净的,没有任何广告。另外,从做百度联盟搜索的网站A 搜索过来的都有这个tn参数,当你点击搜索结果中带“推广”的网站B,做百度“推广”的网站B的户主账户中就会被扣掉一部分费用,其中一部分百度留着,另外一小部分给网站A的户主,因为你从网站A搜索过来的。百度搜索中url的参数解析。
拼接请求快递信息地址发送curl
public function getexpresstest(){
echo("<pre>");
$nu='773159319988898';
$tokenV2=$this->getinfo();
$url='https://express.baidu.com/express/api/express?tokenV2='.$tokenV2.'&nu='.$nu;
var_dump($url);
$header = array (
"Host:express.baidu.com",
"Content-Type:application/x-www-form-urlencoded",//post请求
"Connection: keep-alive",
'Referer:http://www.baidu.com',
//关键作用User-Agent 可是每次爬取结果都是无法爬取到百度搜索的内容,要验证 user-agent没有模拟好,所以不行。
'User-Agent: Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 Safari/537.36',
);
$ch = curl_init ();
curl_setopt ( $ch, CURLOPT_URL, $url );
curl_setopt ( $ch, CURLOPT_HTTPHEADER, $header );
curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, 1 );
$content = curl_exec ( $ch );
if ($content == FALSE) {
echo "error:" . curl_error ( $ch );
}
curl_close ( $ch );
var_dump(json_decode($content));
}返回结果为

这个请求地址在浏览器直接输出明明是正确的,自己请求却返回失败,大可能性是cookie没有或者将请求的参数都加上看看那个是决定性的东西,发现添加cookie后,结果成功了

所以在 https://express.baidu.com/express/api/express?tokenV2=tokenV2&nu=单号 基础上cur还需要加上cookie;
获取tokenV2和cookie
public function getinfo(){
$url = 'https://www.baidu.com/baidu?isource=infinity&iname=baidu&itype=web&tn=02003390_43_hao_pg&ie=utf-8&wd=%E5%BF%AB%E9%80%92';
$header = array (
"Host:www.baidu.com",
"Content-Type:application/x-www-form-urlencoded",//post请求
"Connection: keep-alive",
'Referer:http://www.baidu.com',
//关键作用User-Agent 可是每次爬取结果都是无法爬取到百度搜索的内容,要验证 user-agent没有模拟好,所以不行。
'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36'
);
$ch = curl_init ();
curl_setopt ( $ch, CURLOPT_URL, $url );
curl_setopt ( $ch, CURLOPT_HTTPHEADER, $header );
curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, 1 );
curl_setopt ( $ch, CURLOPT_HEADER, 1 );
$content = curl_exec ( $ch );
if ($content == FALSE) {
echo "error:" . curl_error ( $ch );
}
curl_close ( $ch );
//获取tokenV2
preg_match('/tokenV2=(.*?)"/i', $content, $match);
//获取cookie
preg_match_all('/^Set-Cookie:s*([^;]*)/mi', $content, $matches);
$cookies=implode(';',$matches[1]);
return ['tokenV2'=>$match[1],'cookie'=>$cookies];
}重新拼接请求快递信息地址发送curl
public function getexpresstest(){
echo("<pre>");
$nu='773159319988898';
$info=$this->getinfo();
var_dump($info);
$url='https://express.baidu.com/express/api/express?tokenV2='.$info['tokenV2'].'&nu='.$nu;
$header = array (
"Host:express.baidu.com",
"Content-Type:application/x-www-form-urlencoded",//post请求
"Connection: keep-alive",
'Referer:http://www.baidu.com',
//关键作用User-Agent 可是每次爬取结果都是无法爬取到百度搜索的内容,要验证 user-agent没有模拟好,所以不行。
'User-Agent: Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 Safari/537.36',
'Cookie:'.$info['cookie']
);
$ch = curl_init ();
curl_setopt ( $ch, CURLOPT_URL, $url );
curl_setopt ( $ch, CURLOPT_HTTPHEADER, $header );
curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, 1 );
$content = curl_exec ( $ch );
if ($content == FALSE) {
echo "error:" . curl_error ( $ch );
}
curl_close ( $ch );
var_dump(json_decode($content));
}返回正确数据如下图:

推荐文章

")

")


网上有很多快递查询接口,如快递100、快递鸟等等,但使用接口并不是免费的,如何爬取免费查询快递物流呢,本文仅仅提供爬虫爱好者一个爬虫思路,仅供交流学习请勿用于商业用途。
页面地址: https://www.baidu.com/baidu?isource=infinity&iname=baidu&itype=web&tn=02003390_43_hao_pg&ie=utf-8&wd=%E5%BF%AB%E9%80%92
那么如何解析这个地址呢,右键打开开发者模式,再次点击查询,会发现有新增加的请求地址。如下图:
我们点击该链接,打开预览可以预览响应信息。如下图:
那么这个就是输出给百度这个页面的信息,这个地址就是正确快递信息请求地址。
看标头该地址请求为get请求,如下图:
故复制该地址用postman打开,也可以用其他测试接口软件。如下图:
可以看见正确返回了快递信息。
筛选无用参数发现必填参数为tokenV2和nu,如下图:
地址为:https://express.baidu.com/express/api/express?tokenV2=ax0Pz-mHAJ6vC__gfwtLpcz8OyOz35jgTbRglj_deaYouL6bbtDSKyoXPbwpF4zP&nu=773159319988898
nu为快递单号,tokenV2是如何生成的我们需要找一下,因为到目前为止我们只打开了一个百度快递页面,那么我选择检查源码,看看是否有用的到的信息。
搜索tokenV2果然找到了有用信息,前面页面刷新了一下,所以tokenV2发生了改变,可以再次打开检查上下图是一样的。
所以整个获取快递信息的接口和必填参数已经知道了。首先在快递页面源码里面获取tokenV2,之后与 https://express.baidu.com/express/api/express?tokenV2=tokenV2&nu=单号 即可。下面我用一个简单php程序,复盘一下。
获取tokenV2
public function getinfo(){
$url = 'https://www.baidu.com/s?tn=02003390_43_hao_pg&ie=utf-8&wd=%E5%BF%AB%E9%80%92';
$header = array (
"Host:www.baidu.com",
"Content-Type:application/x-www-form-urlencoded",//post请求
"Connection: keep-alive",
'Referer:http://www.baidu.com',
//关键作用User-Agent 可是每次爬取结果都是无法爬取到百度搜索的内容,要验证 user-agent没有模拟好,所以不行。
'User-Agent: Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 Safari/537.36'
);
$ch = curl_init ();
curl_setopt ( $ch, CURLOPT_URL, $url );
curl_setopt ( $ch, CURLOPT_HTTPHEADER, $header );
curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, 1 );
$content = curl_exec ( $ch );
if ($content == FALSE) {
echo "error:" . curl_error ( $ch );
}
curl_close ( $ch );
// return $content;
$pattern = '/tokenV2=(.*?)"/i';
preg_match($pattern, $content, $match);
return $match[1];
}获取这个tokenV2,curl或者这个页面源码通过正则获取tokenV2,
如果不加tn参数,会有百度安全验证,这样无法获取会不稳定。
tn– 提交搜索请求的来源站点。一个有用的tn:tn=baidulocal 表示百度站内搜索,返回的结果是很干净的,没有任何广告。另外,从做百度联盟搜索的网站A 搜索过来的都有这个tn参数,当你点击搜索结果中带“推广”的网站B,做百度“推广”的网站B的户主账户中就会被扣掉一部分费用,其中一部分百度留着,另外一小部分给网站A的户主,因为你从网站A搜索过来的。百度搜索中url的参数解析。
拼接请求快递信息地址发送curl
public function getexpresstest(){
echo("<pre>");
$nu='773159319988898';
$tokenV2=$this->getinfo();
$url='https://express.baidu.com/express/api/express?tokenV2='.$tokenV2.'&nu='.$nu;
var_dump($url);
$header = array (
"Host:express.baidu.com",
"Content-Type:application/x-www-form-urlencoded",//post请求
"Connection: keep-alive",
'Referer:http://www.baidu.com',
//关键作用User-Agent 可是每次爬取结果都是无法爬取到百度搜索的内容,要验证 user-agent没有模拟好,所以不行。
'User-Agent: Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 Safari/537.36',
);
$ch = curl_init ();
curl_setopt ( $ch, CURLOPT_URL, $url );
curl_setopt ( $ch, CURLOPT_HTTPHEADER, $header );
curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, 1 );
$content = curl_exec ( $ch );
if ($content == FALSE) {
echo "error:" . curl_error ( $ch );
}
curl_close ( $ch );
var_dump(json_decode($content));
}返回结果为
这个请求地址在浏览器直接输出明明是正确的,自己请求却返回失败,大可能性是cookie没有或者将请求的参数都加上看看那个是决定性的东西,发现添加cookie后,结果成功了
所以在 https://express.baidu.com/express/api/express?tokenV2=tokenV2&nu=单号 基础上cur还需要加上cookie;
获取tokenV2和cookie
public function getinfo(){
$url = 'https://www.baidu.com/baidu?isource=infinity&iname=baidu&itype=web&tn=02003390_43_hao_pg&ie=utf-8&wd=%E5%BF%AB%E9%80%92';
$header = array (
"Host:www.baidu.com",
"Content-Type:application/x-www-form-urlencoded",//post请求
"Connection: keep-alive",
'Referer:http://www.baidu.com',
//关键作用User-Agent 可是每次爬取结果都是无法爬取到百度搜索的内容,要验证 user-agent没有模拟好,所以不行。
'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36'
);
$ch = curl_init ();
curl_setopt ( $ch, CURLOPT_URL, $url );
curl_setopt ( $ch, CURLOPT_HTTPHEADER, $header );
curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, 1 );
curl_setopt ( $ch, CURLOPT_HEADER, 1 );
$content = curl_exec ( $ch );
if ($content == FALSE) {
echo "error:" . curl_error ( $ch );
}
curl_close ( $ch );
//获取tokenV2
preg_match('/tokenV2=(.*?)"/i', $content, $match);
//获取cookie
preg_match_all('/^Set-Cookie:s*([^;]*)/mi', $content, $matches);
$cookies=implode(';',$matches[1]);
return ['tokenV2'=>$match[1],'cookie'=>$cookies];
}重新拼接请求快递信息地址发送curl
public function getexpresstest(){
echo("<pre>");
$nu='773159319988898';
$info=$this->getinfo();
var_dump($info);
$url='https://express.baidu.com/express/api/express?tokenV2='.$info['tokenV2'].'&nu='.$nu;
$header = array (
"Host:express.baidu.com",
"Content-Type:application/x-www-form-urlencoded",//post请求
"Connection: keep-alive",
'Referer:http://www.baidu.com',
//关键作用User-Agent 可是每次爬取结果都是无法爬取到百度搜索的内容,要验证 user-agent没有模拟好,所以不行。
'User-Agent: Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 Safari/537.36',
'Cookie:'.$info['cookie']
);
$ch = curl_init ();
curl_setopt ( $ch, CURLOPT_URL, $url );
curl_setopt ( $ch, CURLOPT_HTTPHEADER, $header );
curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, 1 );
$content = curl_exec ( $ch );
if ($content == FALSE) {
echo "error:" . curl_error ( $ch );
}
curl_close ( $ch );
var_dump(json_decode($content));
}返回正确数据如下图:



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
获取这个tokenV2,curl或者这个页面源码通过正则获取tokenV2
最多调用50次
qwe
dasda
dasdas